Design Highlight: Handling data at scale with Portia multi-agent systems
At Portia, we love building in public. Our agent framework is open-source (↗) and we want to involve our community in key design decisions. Recently, we’ve been focussing on improving how agents handle production data at scale in Portia. This has sparked some exciting design discussions that we wanted to share in this blog post. If you find these discussions interesting, we’d love you to be involved in future discussions! Just get in contact (details in block below) - we can’t wait to hear from you.
We’d love to hear from you on the design decisions we’re making 💪 Check out the discussion thread (↗) for this blog post to have your say. If you want to join our wider community too (or just fancy saying hi!), head on over to our discord (↗), our reddit community (↗), or our repo on GitHub (↗) (Give us a ⭐ while you’re there!).
If you’re new to Portia, we’re building a multi-agent framework that’s designed to enable people to run agents reliably in production. Efficiently handling large and complex data sources is one of the key aspects of this, along with agent permissions, observability and reliability. We’ve seen numerous agent prototypes that work well on small datasets in restricted scenarios, but then start to fall over when faced with the scale and complexity of production data. We want to make sure this doesn’t happen when agents are built with Portia. In this blog post, we’ll explore the design decisions we’ve made to enable this.
Real agents handling data at scale
As with all good design discussions, we work backwards from real life use-cases that we’re looking to enable / improve. We’re working with many agent builders and below are a selection of the exciting use-cases we’ve seen that require efficiently processing large data sources:
- A debugging agent that can process many large server log files along with other debug information to diagnose issues.
- A research agent that can process many documents and search results over time as it conducts research into a particular company or person.
- A finance assistant capable of researching over a company’s financial data in a mixture of sheets and docs to answer questions - for example, “from this week’s sales data, identify the top 3 selling products and how their sales are split by Geography”
- A personal assistant capable of having long-running interactions with the user, including taking actions such as scheduling events and sending emails, adapting to their preferences over time
In order to handle each of these use-cases well, our agents need to handle data correctly across complex, multi-step plans without being thrown by large documents or making repetitive mistakes. However, we were finding that these agent builders were hitting a couple of key issues:
- Plan run state overload: Our execution agent has access to the full state of the plan run. When it runs a tool, it stores the output of the tool run into that state for future use. Over time though, if tools were producing large amounts of data, this state could get very large and congested. As this was passed into the LLM, this would then reduce the accuracy with which the execution agent could retrieve the correct information for each step from the plan run state:
- Example: A debugging agent might download and then analyse the logs from 10 different servers and analyse each of them. It might then move on to another task, but the logs from each of those 10 servers would still be in its plan run state, distracting from other useful information when processing future steps.
- Tool calling with large inputs: Our execution agent calls a language model to produce the arguments for calling each tool. However, when we wanted to call a tool with a large argument (e.g. >1k tokens), we would either hit the output token limits of the model or we would hit latencies that would make the system incredibly slow.
- Example: A finance agent might want to read in a large spreadsheet and then pass its contents into a processing tool to extract the key data it needs. We saw occasions where just generating the args for the processing tool took more than 5 minutes because it needed to print out the full contents of the spreadsheet!
We needed to fix these two issues, so our agent builders could stop wrestling with context windows and focus on shipping features.
An aside on long-context models
Before diving into potential solutions, let’s explain why we thought this is a problem worth solving even with the vast context windows seen from the latest models (e.g. Llama4 has a 10m token window (↗) while GPT 4.1 has a 1m context window (↗)). These models have certainly changed the equation - before their arrival, we hit context window limits a lot more than we currently do. However, using these models with large data sources is still difficult and problematic for multiple reasons:
| Accuracy | SOTA models boast strong accuracy scores in needle-in-a-haystack tests, but real scenarios are more complex, requiring reasoning over and connecting different pieces of information in the context, and models get much weaker at this when the context is large. |
|---|---|
| Cost | Filling GPT 4.1’s context window will cost you $2 of processing for every LLM call. Agentic systems typically make many LLM calls, so $2 can quickly make your system very expensive! |
| Latency | As the token number increases, so does the latency, particularly for output tokens. OpenAI states (↗) that while doubling input tokens increases latency 1-5%, doubling output tokens doubles output latency. When compounded with the fact that agentic systems make many LLM calls, this can make systems very sluggish. |
| Failure Modes | Interestingly, language models fail in different ways when the context length gets large. There’s a great study on this from databricks (↗). This adds instability to the system because the prompts you’ve been iterating on in low data scenarios suddenly don’t work as you expected in production. |
Preventing our plan run state becoming overloaded
Given the above, we can’t just rely on long-context models and need to handle the issue with overloading our plan run state within our framework. To solve this, we needed to reduce the size of the context used by our execution agent, and we did this as follows:
- First, we introduced agent memory. For large outputs (the default is above 1k tokens) we store the full value in agent memory with just a reference in the plan run state. This prevents previous large outputs from clogging up the plan run state when they are no longer needed.
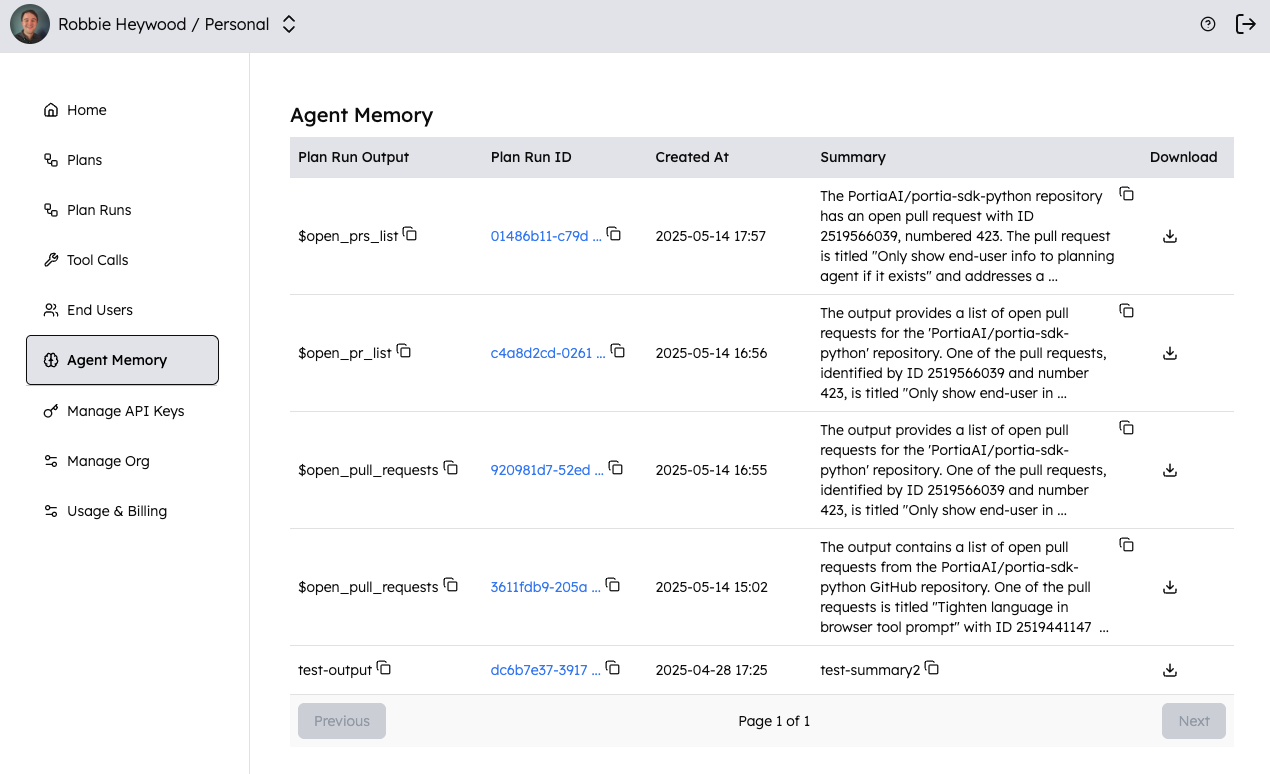
- You can configure where your agent stores memories through our
storage_classconfiguration option (see our docs (↗) for more details). If you choose Portia cloud, you’ll be able to view the memories in our dashboard:
- You can configure where your agent stores memories through our
- Our planner selects inputs for each step of our plan. If one of these inputs is in agent memory, we fetch the value from memory, as we know it is specifically needed for this step. This allows the execution agent to fully utilise the large values in agent memory when needed.
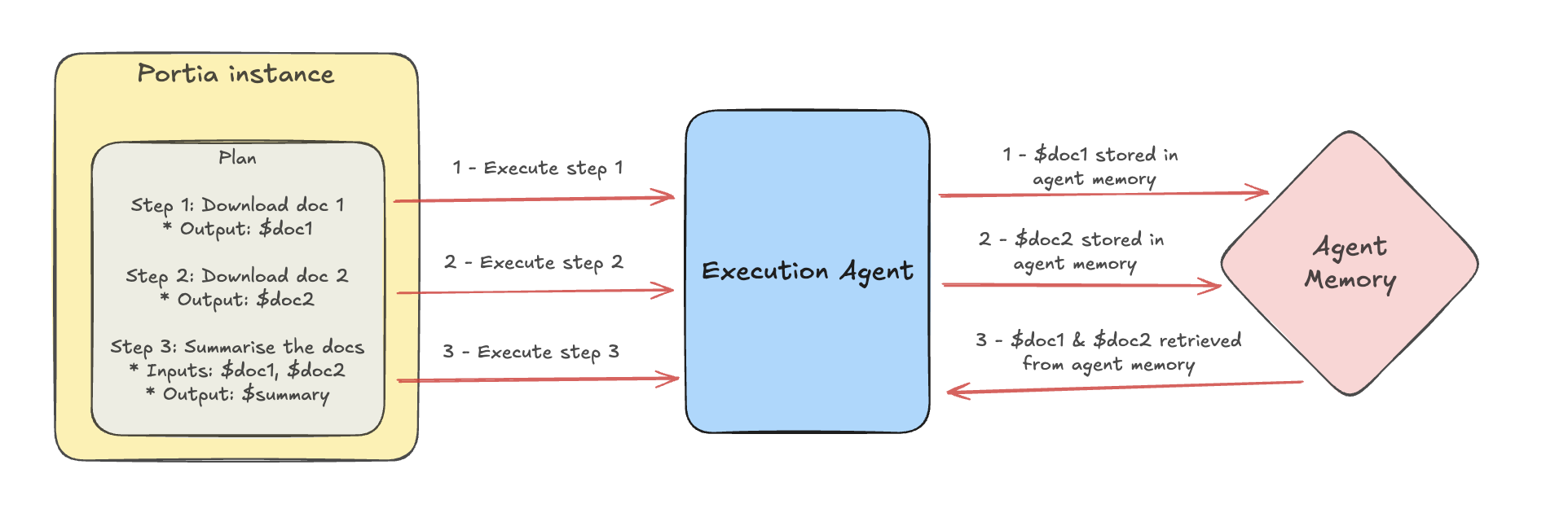
You can check out the code for this feature in this PR (↗) and the docs are here (↗). For our first implementation of agent memory, we decided to only allow pulling the full value from agent memory, rather than indexing the values in a vector database (or other form of database) and allowing queries based on that. A key reason for this (as well as wanting to keep our initial implementation as simple as possible) is that the way memories need to be queried is very task dependent. There are times when a semantic similarity search of memories is required (e.g. a debugging agent looking for similar errors among log files), while other times require filtering on exact values (e.g. a debugging agent looking for logs between two timestamps from a particular service), a projection of the values (e.g. a finance assistant just taking several columns from a spreadsheet) or access to the full value.
Our future vision - a memory agent
Ultimately, we’ll want to support all these patterns, but doing this efficiently requires indexing and querying the memories intelligently based on the task. We believe that this will be best done by a separate memory agent - an agent within our multi-agent system that indexes and queries agent memories so that the required pieces can be retrieved for the task and passed to the execution agent. This clearly adds complexity to the system though! So we wanted to see how our agent builders use agent memory before jumping to conclusions on the best way to index and query the memories.
We’d love to hear what you thought of the decision to not automatically ingest agent memories into a vector database. Is it something you’d like to see? Get involved in the Github discussion (↗) and let us know.
Solving Tool calling with large inputs
Our introduction of agent memory meant that the execution agent was managing the context it sent to the language model much better. However, we were still facing the issue, mentioned above, where the language model struggled to produce large arguments for tools when needed. In order to solve this, we provided the language model with the ability to use templates to input variables. When calling the language model, the execution agent would outline in the prompt that, if the language model simply wanted to use a value from agent memory verbatim, it didn’t have to copy the value out - it could just put, for example {{$large_memory_value}}. We then extended the execution agent to retrieve $large_memory_value from agent memory when this was done and template the value in, so that the tool received the full value.
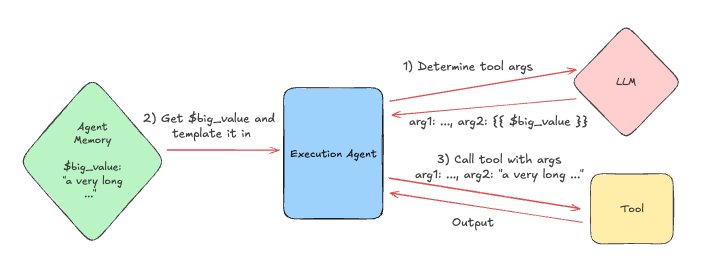
You can check out the code for this feature in this PR: Add ability for execution agent to template large outputs (↗). Interestingly, after a bit of initial tuning, we found that the language model was able to determine correctly whether it should template a variable or not. This has led to a massive improvement in latency and cost of our agents calling tools with large data sources. For example, a personal assistant use-case that involved analysing a large spreadsheet reduced in time from 3-5 minutes to <10s.
What do you think of allowing language models to template variables rather than copy them out fully? Do you have a better approach for this? Get involved in the GitHub discussion (↗) and let us know.
Going forwards
We believe this work sets a great foundation for building multi-agent systems with Portia that handle data at scale, and we’ve got an exciting roadmap of features to keep making this even better:
- Pre-ingest knowledge / memories: we want to allow kicking off our agents with knowledge and memories already loaded, rather than requiring the agent to fetch all the information needed as part of the run
- Improved pagination handling: we want to allow our execution agent to more efficiently use paginated APIs
- Memory agent: as mentioned above, we’re excited about the possibilities opened up by a separate memory agent. Once we’ve got a good idea of how agent memory is being used in its current form, we’d love to start discussions on how this new agent might fit into our system.
We’re really looking forward to finding out what these new large data capabilities will unlock for agent builders working on Portia!
Hopefully you enjoyed this blog post. If you did (or even if you didn’t!), we’d love to hear from you. Did you agree with the design decisions we are taking? Do you think we should take a different approach? If you’ve got thoughts and ideas, we’d love to hear about them in the GitHub discussion (↗) associated with this post. And we love chatting about code even more, so if you’ve got an idea, fork our repo and we’d love to review the code 🚀
Join the conversation
Like this article? – Give us a ⭐ on GitHub (↗). It really helps!
- Browse our website and try our (modest) playground at www.portialabs.ai (↗).
- Head over to our docs at docs.portialabs.ai (↗) or get immersed in our SDK (↗).
- Join the conversation on our Discord channel (↗).
- Watch us embarrass ourselves on our YouTube channel (↗).
- Follow us on Product Hunt (↗).