How Portia ensures reliable agents with evals and our in-house framework
At Portia we spend a lot of time thinking about what it means to make agents reliable and production worthy. Lots of people find it easy to make agents for a proof of concept but much harder to get them into production. It takes a real focus on production readiness and a suite of features to do so (lots of which are available in our SDK as we’ve talked about in previous blog posts):
- User Led Learning for reliable planning
- Agent Memory for large data sets
- Human in the loop clarifications to let agents raise questions back to humans
- Separate planning and execution phases for constrained execution
But today we want to focus on the meta question of how we know that these features help improve the reliability of agents built on top of them by talking about evals.
Evals - What Are They Anyway?
“Evals” is shorthand for evaluations. They’re how we turn the vague question of “is this agent doing the right thing?” into something we can actually measure and repeat.
A good eval works a lot like a unit test or integration test. You give it inputs, run them through the system, and check whether the outputs match what you expected.
Where evals differ from integration or unit tests is in that we are operating in a probabilistic world. LLMs are non-deterministic and thus so is any software built on top of them. Therefore we need to adjust our approach from always asserting something to trying it multiple times and checking the correctness as a percentage.
Consider an example of some software that gets the weather:
Integration test:
GET /weather?location=LONDON
response.status_code = 200
Eval Approach:
Whats the weather in London Today?
The weather in London is 20C
An integration test is generally easy to write because we can make a request to the software and write concrete assertions about the response. With an agent this is much harder. The response is natural language and the format can vary from call to call. Not only that but with agents we are usually dealing with side effects like an email being sent correctly that aren't contained in the response.
Like unit and integrations tests, we think about evals as existing on a spectrum:
- At one end, you have low-level checks. These might confirm that a specific tool was called (a weather tool in the example above), or that a plan has the right structure.
- At the other end, you have full end-to-end tests. These look at whether the agent made the right business decision, even if it found a creative way to get there.
Each type of eval gives you different insight. Low level evals tell you if the system is behaving as expected. High level evals help you understand whether it’s making good decisions for the right reasons.
Evals aren’t necessarily for catching bugs though they certainly can help with this. They’re for asking big performance questions like:
- What happens if we change LLM provider from OpenAI to Gemini?
- Does performance improve if we change the structure or even tone of our prompts?
- How does changing the interface of a tool affect the agent's performance?
Steel Thread
To make evals easier, we built Steel Thread, our internal eval framework, now available to partners using the Portia SDK. Steel Thread is a lightweight Python library designed to help you write, run, and analyze evals for your agent workflows.
It focuses on being:
- Simple: Define your test cases in Python or JSON. Each test specifies inputs, expected outputs, and what success looks like.
- Fast: Built-in concurrency and retries mean you can scale up eval runs without overhead.
- Flexible: You can write low-level metrics that look at fine-grained behavior, or high-level E2E runners that test business outcomes.
- Visualizable: Steel Thread can push results to external layers like LangSmith, making it easy to explore where things are failing and why.
We use it ourselves to test the Portia SDK and the agents built with it. It’s designed for both internal development workflows and user-facing evaluation.
Example: Writing Your First Eval
Let’s walk through a simplified example of using Steel Thread to evaluate an agent. Say you have an agent that makes a decision based on a set of inputs:
import openai
from steel_thread.runner import E2ERunner
from steel_thread.types import EvalOutput
class MyAgent():
def run( # type: ignore
self,
user_id: str,
input_text: str,
) -> EvalOutput:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a smart home assistant tasked with identifying what actions to take."},
{"role": "user", "content": input_text},
],
temperature=0,
)
output_text = response["choices"][0]["message"]["content"].strip().lower()
if "turn on" in output_text and "light" in output_text:
action = "lights_on"
elif "play" in output_text and "jazz" in output_text:
action = "play_music_jazz"
else:
action = "unknown"
return action
You want to test whether it produces the expected outcome given specific inputs. To do this you define a set of test cases, much like you would with normal software testing:
from steel_thread.e2e import E2EEval, EvalOutput
test_cases = [
(
E2EEval(
id="example-1",
inputs={"user_id": "u1", "input_text": "turn on the lights"},
),
EvalOutput(final_output="lights_on", final_error=None),
),
(
E2EEval(
id="example-2",
inputs={"user_id": "u2", "input_text": "play jazz music"},
),
EvalOutput(final_output="play_music_jazz", final_error=None),
),
]
To integrate this with Steel Thread, we define a runner. The runner is a simple class that knows how to call your agent with the inputs from each test case:
class ExampleAgentRunner(E2ERunner):
def run(self, user_id: str, input_text: str) -> EvalOutput:
try:
result = my_agent.run(user_id=user_id, input_text=input_text)
return EvalOutput(final_output=result, final_error=None)
except Exception as e:
return EvalOutput(final_output=None, final_error=e)
Everything is simple enough, up to this point. This is where the magic comes in. We ask steel thread to handle updating the dataset and then to run the evals:
dataset_name = "My Eval Set"
update_dataset_main(dataset_name, eval_dataset)
run_eval_main(
dataset_name,
config,
ExampleAgentRunner(),
EvalOptions(
reps=3,
upload_results=True,
max_concurrency=10,
),
extra_metrics=[],
)
Steel Thread will:
- Concurrently run your agent against the defined test case(s) using the runner according to your concurrency config.
- Score the outputs using a set of default metrics and/or the extra metrics you think are important for your use case.
- Upload the results to your visualization layer of choice.
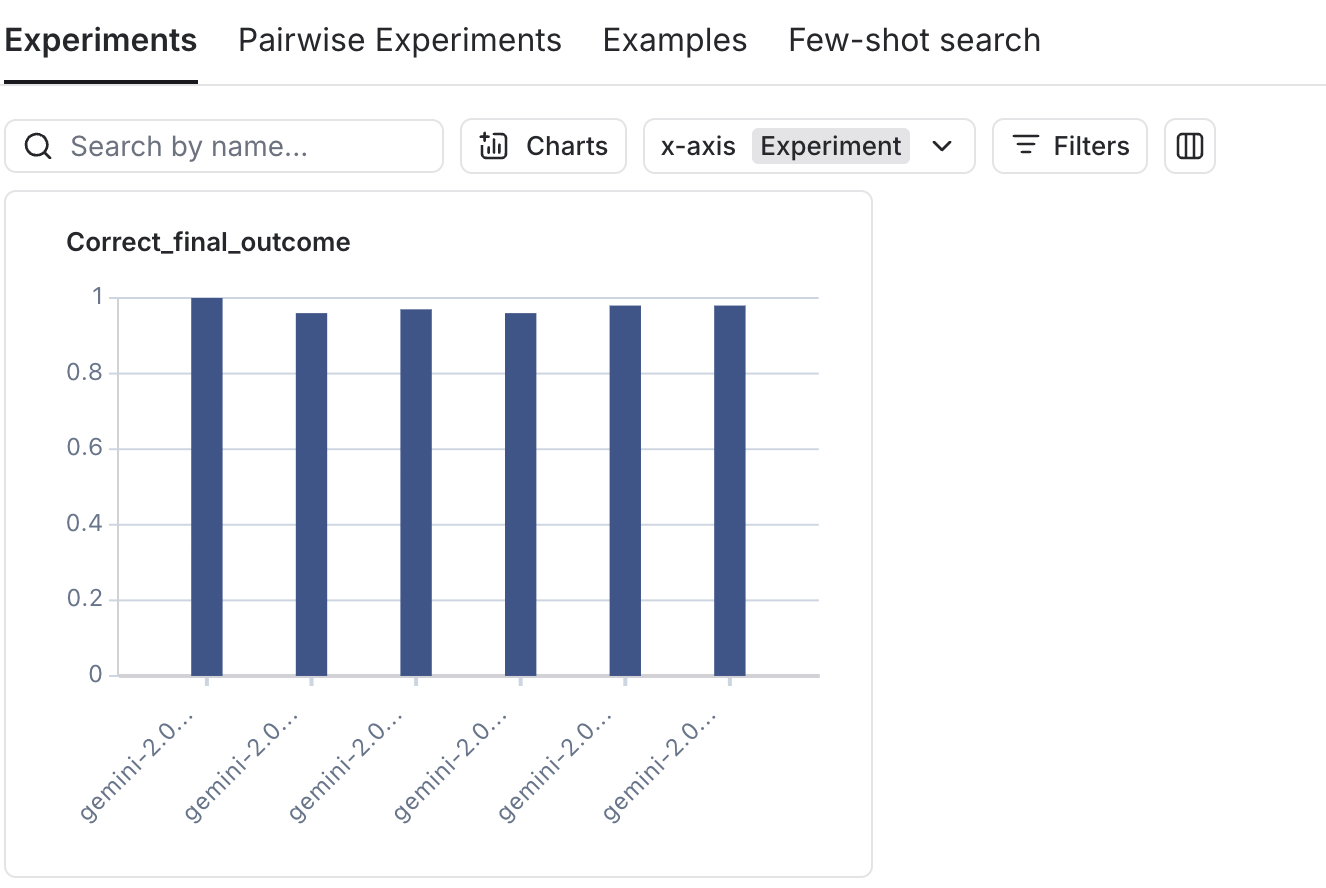
Steel Thread is designed to support multiple visualization layers. You can see below metrics pushed to Langsmith. From this example eval set you can see that our performance on the Correct Final Outcome metric sits between 95-100%. Importantly this is parameterized by things like model choice allowing us to have data driven discussions around changes we want to make.
Adding Extra Metrics
In addition to checking whether the agent returns the correct output, sometimes we care about how the agent answers, for example, how concise or verbose its responses.
Steel Thread makes it easy to define your own custom metrics by subclassing the Metric base class. Here's a simple example of a metric that gives higher scores to shorter outputs:
from steel_thread.metrics import Metric, EvaluationResult
from steel_thread.types import Run, Example
class ShortOutputPreferred(Metric):
"""Reward shorter outputs (under 20 tokens) with a score of 1."""
def evaluate_run(
self,
run: Run,
example: Example | None = None,
evaluator_run_id: uuid.UUID | None = None,
) -> EvaluationResult:
output = run.outputs or ""
word_count = len(output.split())
return EvaluationResult(
key="short_output_preferred",
score=1.0 if word_count <= 20 else 0.0,
)
How We Use Steel Thread
At Portia, Steel Thread is a core part of how we build and validate agentic systems. We use it to continuously measure reliability, correctness, and regressions across different layers of our platform. A few examples:
End-to-End Use Case Testing
We write end-to-end evals for common user journeys whether it's reviewing a customer case, escalating a risk, or generating a compliance summary. These tests help ensure that agents behave as expected across realistic, high-level workflows.
Agent Comparison and A/B Testing
We frequently use our evals to have data driven discussions about feature changes. For example, does introducing a new section of context to the planning prompt affect the performance of our existing evals.
Low-Level Tool Call Verification
We use low-level execution or planning evals to verify that tools are being called with the correct parameters. This is especially useful when agent behavior is compositional or dynamically generated.
Stress-Testing Planning as Tool Count Grows
As our library of tools grows, planning gets harder. We use evals to track how well our agents plan under increasing complexity, including how accurate, efficient, and deterministic they remain.
Why All This Matters
It’s easy to demo something impressive with LLMs. But to deploy an agent in a real-world system with users, data, and risk you need confidence that it will behave consistently and safely.
That’s what evals give you: a feedback loop that allows you to iteratively improve the accuracy and reliability of your agents. You wouldn’t ship software to production without tests and you shouldn’t ship agents to production without evals.
As agents become more complex, the teams that win will be the ones who can reason about behavior, not just improvise it. We hope Steel Thread helps you do that.
Steel Thread is available today to our design partners - get in contact with us at hello@portialabs.ai if you're interested!